

Important Note: The presentation below was based on the state of the research in 2015. For a 2018 Update, please see, "Research on Student Ratings Continues to Evolve. We Should, Too."
A few weeks ago, we published a piece in which I argued that nearly everything written about student evaluations on the internet is a form of academic click bait, and that there is often little-to-no relationship between the viral success of these pieces and the quality of their arguments.
I was, of course, aware of the irony of making such claims on the internet, particularly via a blog post that intentionally avoided the literature I called on all of us to read. And as this piece got a great deal of attention in the days after it was posted, I couldn’t help but smile as my intuition on these matters was confirmed.
Not that we didn't have an idea this would happen. We chose to launch our new blog with a post on student evaluations for precisely this reason. We knew we wouldn't be able to mirror the sophistication of the research literature in this venue, but we hoped a provocative post would draw a wide and diverse audience into our conversations.
And we were not disappointed on that front. As the post grew in popularity, discussions began to sprout up in a variety of places, and it was difficult to keep up with the many thoughtful questions you all raised in comment sections, on social media, and via personal e-mails. It was immediately clear that many of you wanted to know more about the literature, but also that—if I wanted to continue my day job—it might behoove me to consolidate my responses into a single follow-up post.
So today I want to respond to some of the most important questions I have received over the last few weeks. As with the initial post, however, readers will be sure to get more satisfying answers by turning to the peer-reviewed literature itself. I hope the informal answers I give below can help to guide further investigation, or at the very least, serve to slightly nuance future water cooler conversations.
ARE YOU ARGUING THAT STUDENT EVALUATIONS GET AN 'A'?
Not at all. And I wasn’t even arguing they get a "Gentleman's C." I was simply trying to argue that the research literature, taken as a whole, is not reflected in hyperbolic claims like "Student Evaluations Get an 'F.'" That doesn't mean I think it supports a similarly un-nuanced claim in the opposite direction.
So what grade would I give?
I would object to the idea of assigning a grade in the first place. But, if pressed, I would say something like the following:
For some purposes, and in some contexts, certain instruments and practices associated with student evaluations almost certainly get an F. But for others, they almost certainly get an A. And just as often, the grade should sit somewhere in the middle of the curve. Most of the time, however, the instruments and practices associated with student evaluations cannot be graded in any definitive way.
I think you can see why NPR won't be calling on me to title future posts on the subject.
And this answer is really a hedge, isn't it? It doesn't go very far to answer the question that is usually at the root of most discussions, which is something like, "Is it appropriate for my university to use our instrument in the specific ways that it does?"
But part of the point here is that, although the research literature can guide the assessment of student evaluation practices at your institution, the guidance it provides is dependent upon the way you answer four further questions:
- What purposes are the student evaluations on your campus attempting to serve? (To help faculty improve their teaching? To help administrators make personnel decisions? To help students select their courses?)
- What does the instrument on your campus actually look like? (Is the design and administration consistent with research-validated instruments? Does it produce results that are consistent with your goals? Are you sure?)
- How is your evaluation system administered in practice? (How is it delivered, how are the results interpreted, and how are these results translated into further practices on campus? Are they consistent with the recommendations of those who validated your instrument?) [1]
- What is the context in which your evaluation system is being deployed? (Research institution? Liberal Arts College? On-line courses? Lectures? Labs? Project-Based Learning? Has the instrument you have been using been validated in similar contexts?)
Because every institution will provide very different answers to these questions, the literature can and does suggest that some systems deserve an 'F' while others deserve an 'A.' Popular essays that assign failing grades to ALL systems ignore these important considerations.
SO THEN YOU AGREE THAT SOME INSTRUMENTS AND PRACTICES ASSOCIATED WITH STUDENT EVALUATIONS ARE INAPPROPRIATE? IF SO, SHOULDN'T WE THANK THE MEDIA FOR CALLING THIS TO OUR ATTENTION?
Before answering this question, it is important to note that when we ask about the "appropriateness" of any given evaluation practice, we are often asking two very different questions rolled into one. The first is an scientific question, asking whether a specific evaluation practice is an appropriate means of securing accurate and reliable measurements. The second is an ethical question, asking whether the outcomes of this practice are fair or just. This distinction is important to understand because it may be the case that student evaluations can provide accurate and reliable measures of empirical realities, while remaining ethically inappropriate measures of whose careers should be secured or rewarded (more on this below).
At any rate, I do agree that student evaluation systems are being used in inappropriate ways on many campuses. And that the mistakes are both scientific and ethical. I am also more than happy to support those who are calling attention to these problems in the press. The issue I take with the current coverage is that critiques of specific practices are often presented as critiques of the entire enterprise. And if there are, as I believe, uses of student evaluations that are both scientifically and ethically appropriate, that blanket condemnation is harmful.
WHAT ARE THE MOST COMMON STUDENT EVALUATION MISTAKES?
As an ethicist, there is nothing that would please me more than an extended discussion of the ethically inappropriate uses of student evaluations. Unfortunately, the research literature has very little to say about such issues. It does, however, have a great deal to say about common practices that threaten the empirical validity and reliability of these systems.
And on that front, the greatest sins seem to take place at the level of interpretation, when users with little knowledge of statistics misinterpret the meaning of various results. Many mistakes can and have been made in this domain, but the three greatest appear to be the following:
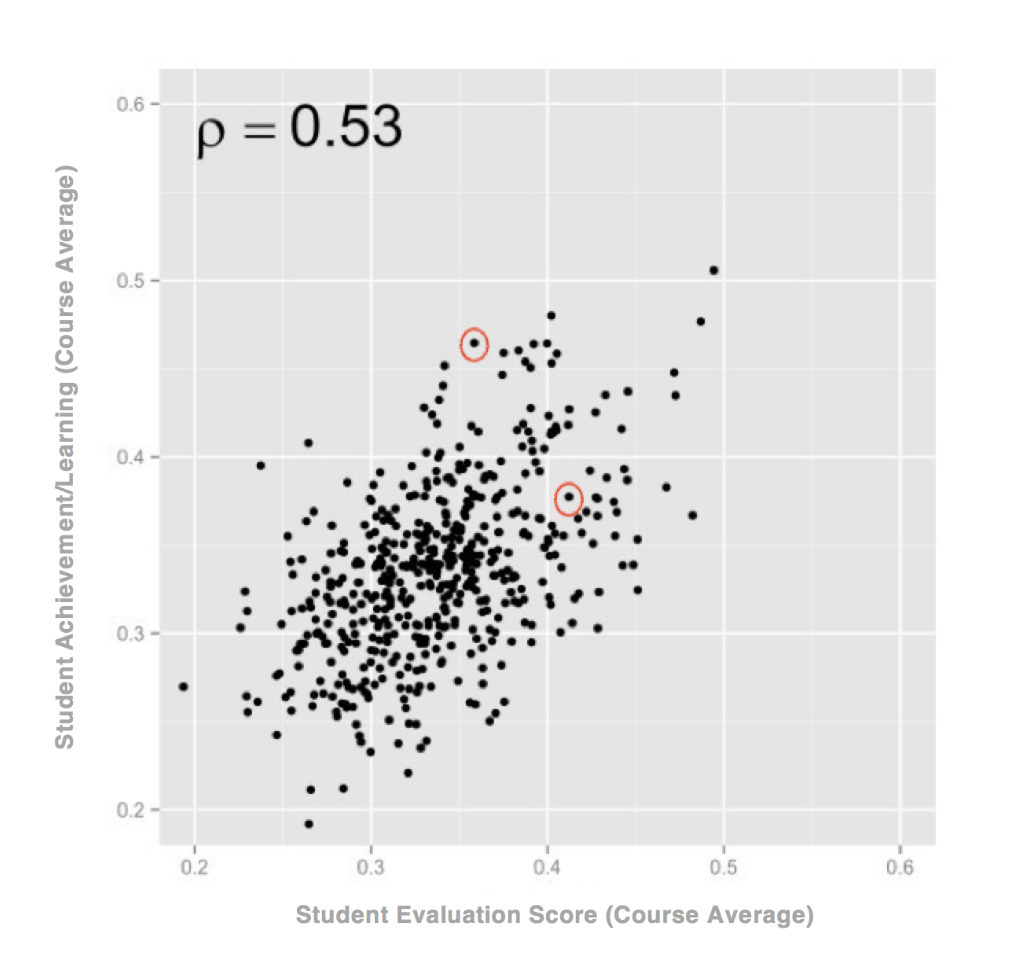
- Too many decision makers assume that when the average scores of two instructors differ, the instructor with the higher score is clearly a more effective teacher than the instructor with the lower score. This practice is a problem for multiple reasons, not all of which can be addressed here. But the most important is that it fails to recognize the reality highlighted in my earlier post: that not even well-validated instruments can produce a result that perfectly correlates with student achievement. To give you a sense of what this means, the chart below represents a hypothetical scatter plot of data with a .53 correlation (a bit better than the correlation found in many studies of well-validated student evaluation instruments). You can clearly see that the data are related; as the evaluation scores rise, so too does student achievement. Yet, you can also see that when a decision maker looks at any two courses, the results could be flipped. In the case of the two data points highlighted in red, we can see that the instructor with the lower evaluation score actually produced more learning than the instructor with the higher score. But that individual case does not make the relationship between the data, in the aggregate, any less correlated.
- Evaluators and faculty alike are too quick to lock on to the response of a single student (whether quantitative or qualitative) as if it were likely to be an accurate picture of something that happened in the course. This is a problem because, to the extent that results have been found to be valid and reliable, it has been the course average, not the scores of individual students.
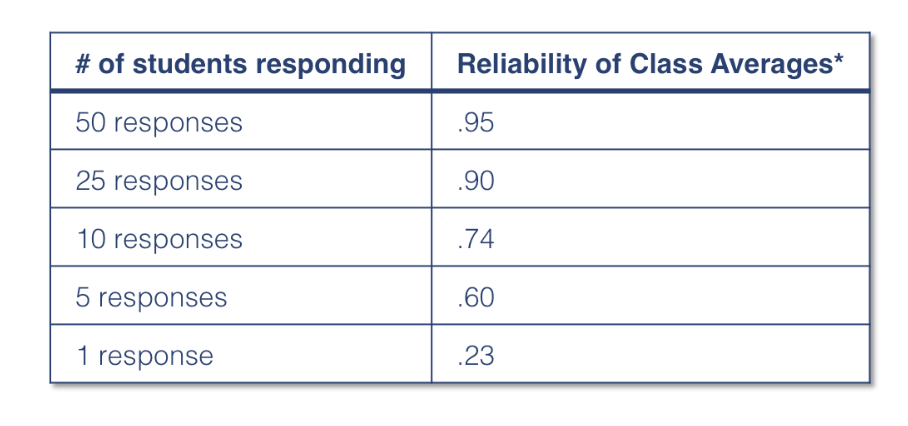
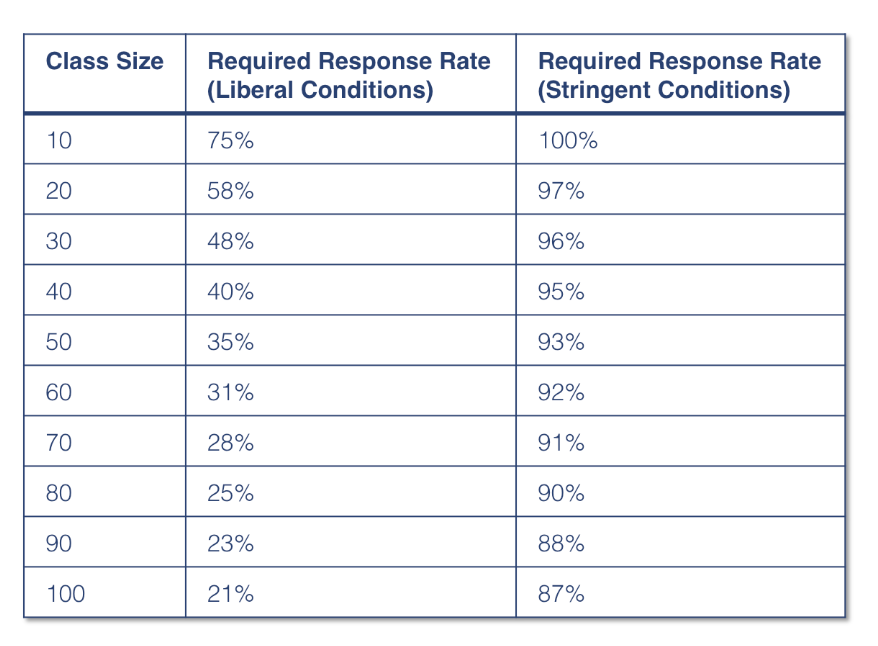
- Finally, and perhaps most importantly, too many decision makers assume that evaluation scores are equally reliable, regardless of class size or response rate. As the charts below indicate, class size and response rates have dramatic effects on reliability.
WHY SHOULD WE BELIEVE THAT "MOST STUDIES" HAVE FOUND A .5 CORRELATION BETWEEN EVALUATIONS AND STUDENT ACHIEVEMENT? AND DOES THIS RESULT REALLY MATTER IF THOSE STUDIES WERE POORLY DESIGNED?
These are fair questions, and ones that should be addressed by anyone attempting to defend the validity of student evaluations.
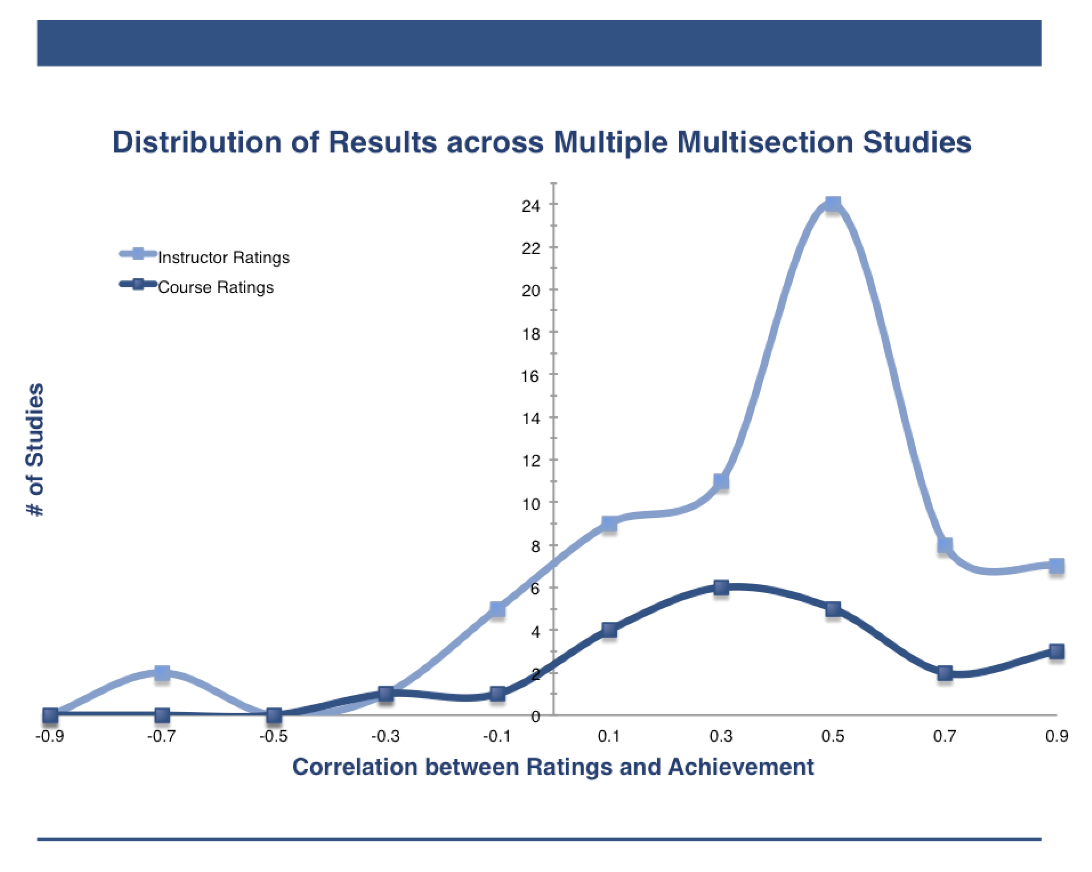
Although the extensive literature has produced variable results over the last century, it is possible to make that literature speak with a single voice. One of the most straightforward methods of synthesizing the literature is to simply read all that has been written and produce a narrative account. This has been done a number of times, and the majority of these reviews come to the conclusion that there is modest support for the validity of student evaluations. [2] If one prefers quantitative methods, another method is to simply count the number of studies that have found a positive correlation and compare it to the number that have found no correlation or a negative correlation. Or, even better, one could chart the distribution of results from each of the studies, much like you see in the following chart (this is simply an example; if we were to do this for the entire literature, the # of studies would be much larger):
There are, of course, problems with both of these approaches. The qualitative narratives seem to allow too much room for researchers to interpret the literature in the direction of their preferred conclusions. And the quantitative "counting" method only makes sense if the studies included are relatively similar in design and quality, which is not at all the case with this literature.
To get around these problems, social scientists often turn to quantitative "meta-analyses" that combine results by creating strict guidelines for which studies can and cannot be included, coding those studies according to their various features, and producing a result via a model that takes account of this variance. As early as 1984, six different meta-analyses on the relationship between student evaluations and student achievement had already been produced. [3] And in 1988, an analysis of these meta-analyses was produced.[4] Although there was some small variance in the initial meta-analyses, the 1988 study and many later analyses agree that Peter Cohen's methods were among the best and that the results of his studies should be trusted. [5]
The chart above is actually a graph of the results from the 41 studies included in Cohen's initial meta-analysis. When these results were put into his model, he found that the literature suggests a correlation of around .47 between instructor ratings and student achievement.
The primary reason Cohen's results are so compelling is that the 41 studies he included were all relatively similar and well-designed. As the title of the chart indicates, Cohen only included "multisection validity studies" in his analysis. These are studies where students were assigned to different sections of the same course (often randomly) and then given common exams. The average exam performance of each section was then correlated with the average evaluation for the instructor of that section. [6]
So while critics are right to question the research design of the studies that find positive correlations, it is hard to imagine a higher bar than these studies. Indeed, many of the most recent studies that find a negative correlation have failed to meet this bar. One (debatable) exception to this is the new trend in the economics literature to measure learning in terms of future grades, rather than performance on a common, standardized exam. [7] I find this approach interesting, but I'm not fully convinced it is without problems.
AREN'T THE STUDIES YOU CITE RATHER OLD, AND AREN'T CURRENT STUDENTS AND PEDAGOGY DISTINCT ENOUGH TO RAISE SERIOUS QUESTIONS ABOUT THE APPLICABILITY OF EARLIER STUDIES?
Insofar as scientists in a variety of fields often rely upon old results (particularly once something has been found as consistently as these meta-analyses show), it’s not necessarily a problem for these results to be old. And because there haven’t been follow up meta-analyses using the same methods that undermine the result, I’m relatively confident that the results still hold.
That said, in her piece “Time to Raise Questions About Student Ratings,” Linda Nilson raises some interesting questions about the use of old data in this domain. She admits that the initial results were perfectly valid, but questions their applicability to the contemporary context. More specifically, she thinks that because today's students "devalue academics and reflection," have "an inflated estimation of their own abilities and knowledge," are "unaccustomed to working hard," and are more willing to lie than students from the 70s, we shouldn't assume that the results will continue to hold. [8]
Setting aside the question of whether these descriptions of current students are accurate (they certainly don't describe the students in my classroom), Nilson's point is well taken. If the context in which today's evaluation systems are administered is radically distinct from the context of the initial studies, we should proceed with caution. And this is true with respect to the types of students we teach, as well as the way we teach. Most of the 41 studies in Cohen's meta-analysis employed lecture as the primary means of content delivery and multiple-choice exams as the primary means of assessment. It's possible that newer pedagogies may interact with the older instruments in unexpected ways.
As important as these questions are, they warrant caution, not rejection. It's possible the results are no longer valid, but it is also possible that they are. What we need is further research. Nilson draws our attention to a few contemporary studies attempting to do just that, but they draw on the old information or use methods that are distinct from the earlier methods (whether that be relying on future grades as the measure of student learning, or correlating individual student ratings with individual achievement). If we want to know whether Cohen's results still hold, we need to replicate the methodology of the early multisection validity studies in the contemporary context. [9]
WHAT ABOUT THAT STUDY THAT SHOWED STUDENTS MAKE JUDGMENTS ABOUT THEIR TEACHERS IN 30 SECONDS? OR THE ONE WHERE THEY HIRED AN ACTOR?
If you hang around higher education circles long enough, you will eventually hear about one of two classic studies that seem to demonstrate, in rather dramatic fashion, that student evaluations have little to do with student learning.
The first study, published in 1975, hired an attractive actor to play "Dr. Fox," and asked him to present a lecture of gibberish as enthusiastically as possible. [10] After the lecture was complete, the attendees (not exactly students, in this case) were asked to rate the quality of the lecture, and Dr. Fox got high marks (you can watch the video here; it's hilarious). The second study is more recent (1993), and asks participants to rate teachers on 13 different personality traits on the basis of 3, 10-second videos of actual teaching. The results were then correlated with the scores the instructor received on their actual end of semester evaluations (completed by their actual students), and many of the the quickly-judged personality traits correlated quite strongly. [11]
Given these results, what are we to make of claims that there is a correlation between evaluations and achievement? How can there be if students assign high scores for gibberish or before they have even been taught? And what about those studies that suggest more attractive instructors receive higher evaluations? How can that have anything to do with learning?
The easiest way to answer this question is to remind readers of the meaning of correlation coefficients. When the correlation between two variables is .5 (which appears to be the best we can hope for with student ratings), that means that 75% of the variance is explained by other factors. So, it is possible that student learning, enthusiasm, non-verbal communication, and attractiveness all influence the outcome. If so, these studies needn't undermine Cohen's results; they might simply be filling in the rest of the story.
It is also possible that variables like enthusiasm, nonverbal cues, and perhaps even attractiveness, might have independent effects on student learning. So, for example, it may be the case that enthusiastic teachers have an easier time keeping students engaged, that engaged students are more likely to study, and that those who study are more likely to learn. In this were the case, we would expect all three variables (enthusiasm, learning, and evaluations) to correlate with one another, and showing that they do would actually validate, rather than invalidate, the measure.
In fact, for precisely this reason, the authors of the attractiveness study cited above are careful to note that their study doesn't necessarily invalidate student ratings. It is possible, they argue, that "good-looking professors are more self-confident because their beauty previously generated better treatment by other people," or that "students simply pay more attention to attractive professors." And if an instructor's self-confidence or the attention of their students leads to more learning, "it is their beauty that is the ultimate determinant of their teaching success." [12]
None of us want to imagine a world where this could be true, but what if it were? What implications would it have for the use of student evaluations?
This is a situation in which the distinction between the empirical validity of a measure and the ethical validity of its use is particularly relevant. In a world where personal traits beyond the instructor's control influence student learning, an empirically accurate measure of student learning would be an ethically problematic tool for making personnel decisions (to put it mildly).
Luckily for us, we may not have to consider such a possibility because we have good reason to question whether the studies highlighted above actually demonstrate what many have claimed they demonstrate.
In the case of the Dr. Fox study, a recent replication found that, although students enjoyed the nonsensical lecture, when they were asked whether they learned from the lecture (a new question), it became clear that they had not been seduced into believing they had learned. [13] This suggests that one of the keys to designing student evaluation forms is to ask students, quite explicitly, what they have learned.
In the case of the 30-second videos, it is important to note that the authors did not design this study to test the validity of student evaluation instruments. Nor do they challenge their validity in their conclusions. Instead, their entire research design assumes they are valid, and uses this validity to argue that "our consensual impressions of others, even when based on very brief observations of nonverbal behavior, can sometimes be unexpectedly accurate” [emphasis mine]. Moreover, the second half of their study runs the same experiment, but correlates the 30-second impressions with the evaluations of trained observers, and the correlations are equally strong. So if we think these results undermine the validity of student ratings, they must also undermine the validity of expert observations.
Finally, recent replications of the attractiveness study have found that, if you control for omitted variable bias, the effects of attractiveness seem to disappear. [14]
IF STUDENT EVALUATIONS CONTINUE TO BE ABUSED, WOULDN'T WE BE BETTER OFF WITHOUT THEM?
I want to end by addressing a question that was never explicitly asked, but that I believe was lurking beneath the surface of many conversations. If, even in the best case scenarios, the correlation between student evaluations and student learning is .5, and if many think that decision makers use these results in manners that are both scientifically and ethically suspect, aren't we better off lobbying for their demise?
Given how much time I've put into studying this issue (and sharing what I've found), it may not surprise you to learn that my answer to this question is unequivocally, "no." And the reason for this circles back to what I take to be the most important of the six points I made in my first post on these issues: that, despite all of the problems with student evaluations, we have yet to find an alternative measure that correlates as strongly with student learning.
As a teacher, there is nothing I care more about than figuring out what I can do to help my students learn. And as an assistant director of a teaching center, I am eager to work with faculty who want to figure out what they can do to help their students learn, as well. But understanding how students learn is an incredibly tricky task. And figuring out the best way for our students to learn our material in the context of our classroom is even more complex. Our goals are often moving targets, many of the methods we once considered ideal turn out to be a waste of time, and sometimes new ideas that work well in one context fail miserably in others. The scholarship on teaching and learning is sometimes helpful, but it is often just as likely to be inconclusive.
So as both a faculty member and an administrator, I am eager to embrace any instrument that provides any degree of insight into student learning and its relationship to instructional techniques. And this is so not because it will allow me (or anyone else) to make summative decisions about the careers of faculty, but because it will allow all of us to better understand student learning and improve our teaching, as a result. [15]
In many ways, working to improve student learning in our classrooms is like flying a plane through a dense fog. And in that context, it is hard to imagine giving up the best tool we have to see things more clearly.
Yes, student evaluations are imperfect. They don't clear away the fog completely, and sometimes they add their own distractions. But without them, we might as well be flying blind.
[1] In the literature, a failure to ensure that an instrument is used as intended is described as a failure of "outcome validity." For a more detailed discussion of the various types of validity at stake in the debate about student evaluations, see Onwuegbuzie, Anthony J., Larry G. Daniel, and Kathleen M. T. Collins. “A Meta-Validation Model for Assessing the Score-Validity of Student Teaching Evaluations.” Quality & Quantity 43, no. 2 (April 2009): 197–209. To read a summary of the larger literature that makes use of these categories, see Spooren, Pieter, Bert Brockx, and Dimitri Mortelmans. “On the Validity of Student Evaluation of Teaching The State of the Art.” Review of Educational Research 83, no. 4 (December 1, 2013): 598–642.
[2] See, for example, Costin, Frank, William T. Greenough, and Robert J. Menges. “Student Ratings of College Teaching: Reliability, Validity, and Usefulness.” Review of Educational Research 41, no. 5 (December 1, 1971): 511–35, Kulik, James A., and Wilbert J. McKeachie. “The Evaluation of Teachers in Higher Education.” Review of Research in Education 3, no. 1 (January 1, 1975): 210–40, Feldman, Kenneth A. “Course Characteristics and College Students’ Ratings of Their Teachers: What We Know and What We Don’t.” Research in Higher Education 9, no. 3 (January 1, 1978): 199–242, Marsh, Herbert W. “Students’ Evaluations of University Teaching: Research Findings, Methodological Issues, and Directions for Future Research.” International Journal of Educational Research 11, no. 3 (1987): 253–388, Abrami, Philip C., Sylvia D’Apollonia, and Peter A. Cohen. “Validity of Student Ratings of Instruction: What We Know and What We Do Not.” Journal of Educational Psychology 82, no. 2 (1990): 219–31, Ory, John C., and Katherine Ryan. “How Do Student Ratings Measure Up to a New Validity Framework?” New Directions for Institutional Research 2001, no. 109 (March 1, 2001): 27–44, and Spooren, Pieter, Bert Brockx, and Dimitri Mortelmans. “On the Validity of Student Evaluation of Teaching The State of the Art.” Review of Educational Research 83, no. 4 (December 1, 2013): 598–642.
[3] The six were: Cohen, Peter A. “Student Ratings of Instruction and Student Achievement: A Meta-Analysis of Multisection Validity Studies.” Review of Educational Research 51, no. 3 (October 1, 1981): 281–309, Cohen, Peter A. “Validity of Student Ratings in Psychology Courses: A Research Synthesis.” Teaching of Psychology 9, no. 2 (April 1982): 78, Dowell, David A., and James A. Neal. “A Selective Review of the Validity of Student Ratings of Teachings.” The Journal of Higher Education 53, no. 1 (January 1, 1982): 51–62, Cohen, Peter A. “Comment on A Selective Review of the Validity of Student Ratings of Teaching.” The Journal of Higher Education 54, no. 4 (July 1, 1983): 448–58, McCallum, L. W. “A Meta-Analysis of Course Evaluation Data and Its Use in the Tenure Decision.” Research in Higher Education 21, no. 2 (June 1984): 150–58, and Abrami, Philip C. “Using Meta-Analytic Techniques to Review the Instructional Evaluation Literature.” Postsecondary Education Newsletter 6 (1984): 8.
[4] Abrami, Philip C., Peter A. Cohen, and Sylvia d’ Apollonia. “Implementation Problems in Meta-Analysis.” Review of Educational Research 58, no. 2 (July 1, 1988): 151–79.
[5] See, for example, Feldman, Kenneth A. “The Association between Student Ratings of Specific Instructional Dimensions and Student Achievement: Refining and Extending the Synthesis of Data from Multisection Validity Studies.” Research in Higher Education 30, no. 6 (December 1, 1989): 583–645 and Clayson, Dennis E. “Student Evaluations of Teaching: Are They Related to What Students Learn? A Meta-Analysis and Review of the Literature.” Journal of Marketing Education 31, no. 1 (April 1, 2009): 26, where he argues that "There are no mistakes large enough in Cohen's meta-analysis to invalidate his conclusion that learning is positively related to SET."
[6] For examples of the kinds of multisection validity studies included, see Greenwood, Gordon E., Al Hazelton, Albert B. Smith, and William B. Ware. “A Study of the Validity of Four Types of Student Ratings of College Teaching Assessed on a Criterion of Student Achievement Gains.” Research in Higher Education 5, no. 2 (January 1, 1976): 171–78, Centra, John A. “Student Ratings of Instruction and Their Relationship to Student Learning.” American Educational Research Journal 14, no. 1 (January 1, 1977): 17–24, Braskamp, Larry A., Darrel Caulley, and Frank Costin. “Student Ratings and Instructor Self-Ratings and Their Relationship to Student Achievement.” American Educational Research Journal 16, no. 3 (July 1, 1979): 295–306, Marsh, Herbert W., and J. U. Overall. “Validity of Students’ Evaluations of Teaching Effectiveness: Cognitive and Affective Criteria.” Journal of Educational Psychology 72, no. 4 (August 1980): 468–75.
[7] The two most famous studies finding negative correlations with this approach are Carrell, Scott E., and James E. West. “Does Professor Quality Matter? Evidence from Random Assignment of Students to Professors.” Journal of Political Economy 118, no. 3 (June 1, 2010): 409–32 and Braga, Michela, Marco Paccagnella, and Michele Pellizzari. “Evaluating Students’ Evaluations of Professors.” Economics of Education Review 41 (August 2014): 71–88.
[8] Nilson, Linda B. “Time to Raise Questions About Student Ratings.” To Improve the Academy 31 (2012): 213–28.
[9] It should be noted that although there have been few contemporary studies that employ the multisection design, there are many instruments, like IDEA SRI, that have been validated in the contemporary context.
[10] Ware, J. E., and R. G. Williams. “The Dr. Fox Effect: A Study of Lecturer Effectiveness and Ratings of Instruction.” Journal of Medical Education 50, no. 2 (February 1975): 149–56. [Description of Study]
[11] Ambady, Nalini, and Robert Rosenthal. “Half a Minute: Predicting Teacher Evaluations from Thin Slices of Nonverbal Behavior and Physical Attractiveness.” Journal of Personality and Social Psychology 64, no. 3 (1993): 431–41.
[12] Hamermesh, Daniel S., and Amy Parker. “Beauty in the Classroom: Instructors’ Pulchritude and Putative Pedagogical Productivity.” Economics of Education Review 24, no. 4 (August 2005): 369–76.
[13] Peer, Eyal, and Elisha Babad. “The Doctor Fox Research (1973) Rerevisited: ‘Educational Seduction’ Ruled Out.” Journal of Educational Psychology 106, no. 1 (February 2014): 36–45.
[14] Campbell, Heather E., Karen Gerdes, and Sue Steiner. “What’s Looks Got to Do with It? Instructor Appearance and Student Evaluations of Teaching.” Journal of Policy Analysis and Management 24, no. 3 (June 1, 2005): 611–20.
[15] A great deal of research has been done on whether faculty actually use student evaluation results in this way (i.e., to improve their teaching). To read more about this research, most of which suggests faculty need to be able to consult with others about their results, see Kember, David, Doris Y. P. Leung, and K. P. Kwan. “Does the Use of Student Feedback Questionnaires Improve the Overall Quality of Teaching?” Assessment & Evaluation in Higher Education 27, no. 5 (September 1, 2002): 411–25, Penny, Angela R., and Robert Coe. “Effectiveness of Consultation on Student Ratings Feedback: A Meta-Analysis.” Review of Educational Research 74, no. 2 (June 1, 2004): 215–53, Lang, Jonas W. B., and Martin Kersting. “Regular Feedback from Student Ratings of Instruction: Do College Teachers Improve Their Ratings in the Long Run?” Instructional Science 35, no. 3 (November 14, 2006): 187–205, Marsh, Herbert W. “Do University Teachers Become More Effective with Experience? A Multilevel Growth Model of Students’ Evaluations of Teaching over 13 Years.” Journal of Educational Psychology 99, no. 4 (November 2007): 775–90, and Dresel, Markus, and Heiner Rindermann. “Counseling University Instructors Based on Student Evaluations of Their Teaching Effectiveness: A Multilevel Test of Its Effectiveness Under Consideration of Bias and Unfairness Variables.” Research in Higher Education 52, no. 7 (January 19, 2011): 717–37.
Posted on July 28, 2015 by Elizabeth Barre and filed under Evaluation.